In brief
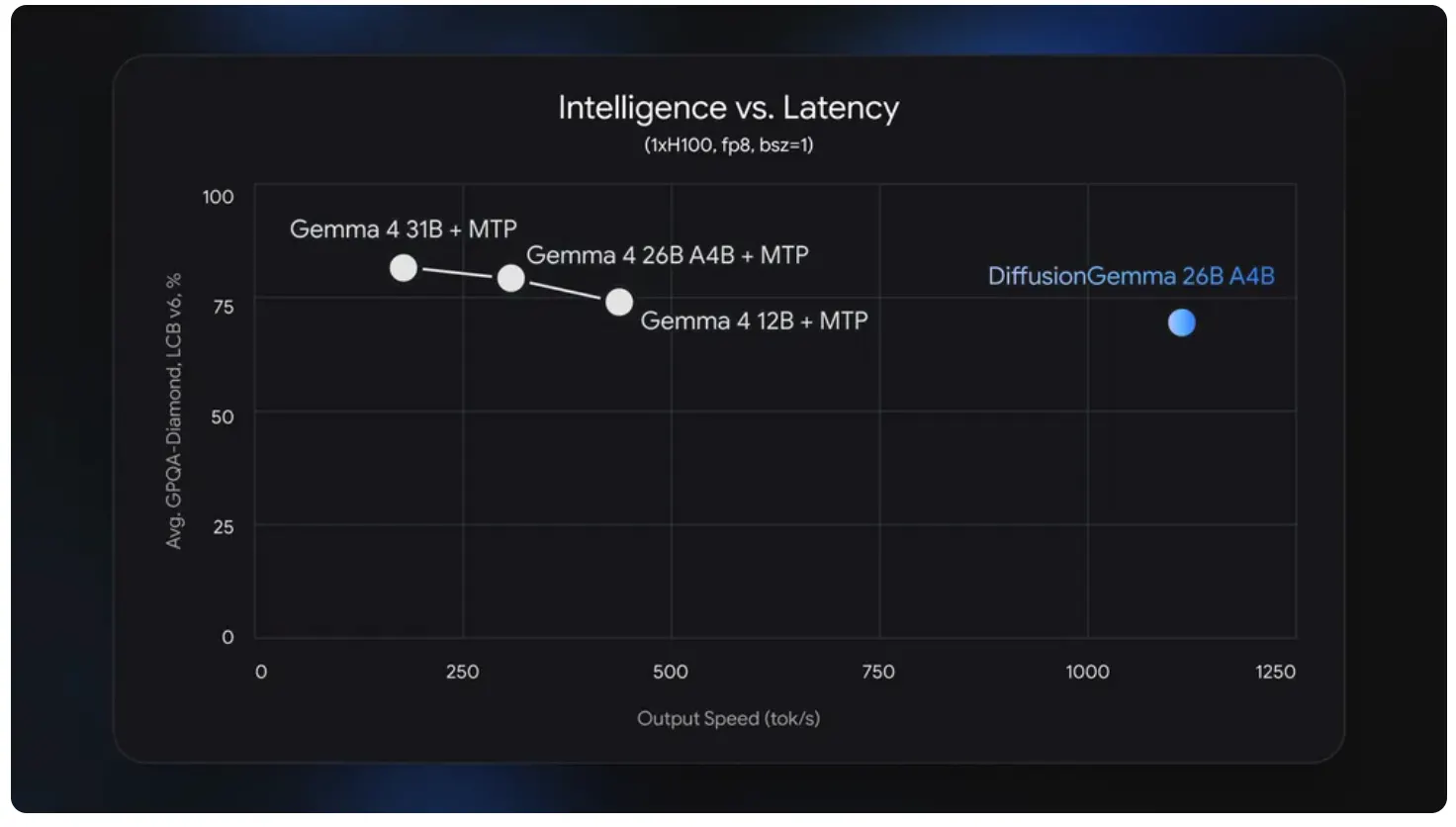
- Google released DiffusionGemma, a free open-weight model that generates entire 256-token blocks simultaneously via text diffusion—hitting over 1,000 tokens per second on an NVIDIA H100, four times faster than standard autoregressive models.
- The custom drafter module DiffusionGemma needs for local inference doesn’t exist in any public runtime yet—not in mlx-lm, not in LM Studio—making it effectively unrunnable on most consumer setups today.
- On NVIDIA NIM, the model arrived preconfigured at 8,192 tokens of context—below the 64,000-token floor that agentic frameworks like Hermes Agent require—meaning autonomous workflows won’t run without manual reconfiguration.
Google dropped DiffusionGemma today, an open model AI that generates text the way image generators create pictures: start with noise, refine until it makes sense. It hits 1,000 tokens per second on an NVIDIA H100. (Tokens are the basic unit of information that an AI model handles.) That means it’s four times faster than regular Gemma. It’s also free, Apache 2.0, with weights on Hugging Face.
The catch, as always, is in the fine print. Per Google’s announcement, the model hits “700+ tokens per second on NVIDIA GeForce RTX 5090.” It also trails standard Gemma 4 on output quality.
Google says so themselves. This is a speed model, not a quality upgrade.
What this actually does
Every LLM you’ve used is a typewriter. One token at a time with each word dependent on the last. That’s how autoregressive architectures work.
DiffusionGemma doesn’t do that. Instead of generating tokens sequentially, it starts with refined chunks of garbled text in parallel. Per Google’s developer guide, it “starts with a canvas of random placeholder tokens” and iteratively locks in confident tokens until the whole block snaps into focus. Two hundred fifty-six tokens per forward pass. The GPU stays busy.
The side effect is bidirectional attention—every token can see every other token while being generated, which is impossible in autoregressive models (they cannot see the future, what is going to be encoded). That makes it unusually good at tasks where the end of the answer constrains the beginning: code infilling, structured output, constraint-heavy problems, etc. Google fine-tuned a version to solve Sudoku as a demo. The base model got roughly 0% of puzzles right.
The fine-tuned version hit 80%.
Text diffusion has been a research project for years. MDLM, SEDD, LLaDA, Dream—academic models that proved the approach worked at small scales and mostly stayed as proof of concepts. Inception Labs shipped Mercury 2 in February 2026 as the first commercial diffusion reasoning model, claiming speeds five times faster than speed-optimized competitors.
But none of that was open-weight, and none of it came with day-zero support in vLLM, Hugging Face Transformers, and Unsloth. DiffusionGemma is the first major open release from a tier-one lab.
There’s also a historical irony worth noting. Image generators started as diffusion models (hence the name Stable Diffusion) and are now moving toward autoregressive architectures for better quality. Language models started as autoregressive and are now experimenting with diffusion for speed.
Why it’s a pain to run… for now
Running DiffusionGemma efficiently requires a drafter—a lightweight module that proposes token blocks in parallel, which the main model then verifies in one forward pass. This is called speculative decoding. DFlash is a framework published in early 2026 that uses a small diffusion model as the drafter, enabling over 6x speedup on some tasks. It’s the engine that makes this class of model practical.
The problem: DiffusionGemma needs a specific drafter to run locally via MLX—Apple’s machine learning framework for Apple Silicon. That module doesn’t exist in any public version of mlx-lm, in any open pull request, or in LM Studio’s bundled runtime.
We tried running DiffusionGemma with Hermes through NVIDIA NIM. The model loaded, but then: “agent init failed: Model google/diffusiongemma-26b-a4b-it has a context window of 8,192 tokens, which is below the minimum 64,000 required by Hermes Agent.”
To be precise: DiffusionGemma’s actual context window is 256K tokens. The 8,192 figure was Nvidia messing things up by default, not the model’s architectural limit.
In practice, getting it configured correctly for agentic use requires manual work that most everyday users haven’t figured out yet, and Hermes Agent simply won’t initialize without it. Parallel speed means nothing if the agent can’t boot.
Hopefully, in the next few days, the community will produce better resources to run these models.
Who this is actually for
Developers with NVIDIA RTX 4090 or 5090 hardware building real-time tools—inline editors, autocomplete, code infilling, structured generation. That’s the target. As Decrypt covered in May, Google has been on a steady push to make local inference faster without new hardware.
For researchers, bidirectional generation opens territory that autoregressive models simply can’t reach—protein sequences, mathematical graphs, anything where position N depends on position N+50. That’s not a small thing.
Google launched Gemma 4 under Apache 2.0 in April, and DiffusionGemma continues that strategy. There’s already a draft llama.cpp PR open as of today. When the toolchain catches up, this reaches a much wider audience.
On a machine with a capable discrete GPU, 1,000 tokens per second is real.
Daily Debrief Newsletter
Start every day with the top news stories right now, plus original features, a podcast, videos and more.






















{kind=link}